What Your Sport Watch Can Teach You About Your Running Performance
A linear regression in KNIME shows which factors really impact your pace
Introduction
Once or twice a week, I lace up my running shoes and head out for a loop around my neighbourhood, usually somewhere between 7 and 10 kilometers. Some runs feel light and fast, others feel sluggish and slow. Like most runners, I often wonder: Why does my pace vary so much? Is it the weather? The time of day? Or maybe just me?
Curious to find out, I decided to analyse my own running data. Using metrics from my sport watch. And a bit of public available weather data from the (The Royal Netherlands Meteorological Institute ) KNMI, helped me to I built a regression model to uncover what truly influences my pace per kilometer. Because if I can understand what really matters, maybe I can create the conditions (or habits) for faster runs.
The Goal
The goal was simple: to discover which factors contribute most to my time per kilometer, ‘average pace’ (in seconds). In this case, factors that I suspected might affect my performance. Before running the analysis, I listed all potential predictors and grouped them by source.
- Watch data: Cadence (SPM), Stride Length (cm), Distance (km)
- Weather data: Windspeed, Temperature, Precipitation duration, Sea level pressure
- Derived data: Time of day, Day of week
The KNIME workflow
Like many of my data experiments, I built the analysis in KNIME, an open-source, low-code data science platform. While I run, my sports watch collects data. The data is available in my online account. All data from my sport watch was exported to CSV. I ran a quick data quality check and found two poorly recorded runs, and after removing them, I was left with 118 valid observations.
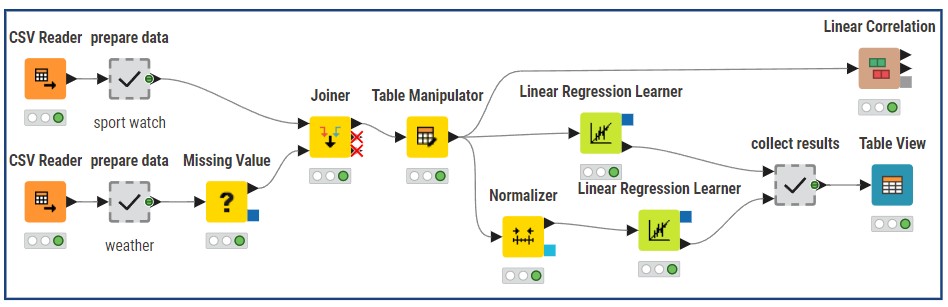
Weather data came from the KNMI dataset of daily climate records. I joined those daily averages, wind speed, temperature, precipitation, and air pressure to my running data by date. Ideally, I’d use hourly data matched to my exact running time, but that wasn’t available.
To avoid losing records due to missing weather values, I replaced the few missing points (Missing Value node) with yearly averages — a small compromise to keep the dataset consistent.
Looking for Correlations
My first step was to explore the correlations between my average pace (seconds per kilometer) and the variables I expected to influence it. The results are shown in the table below.
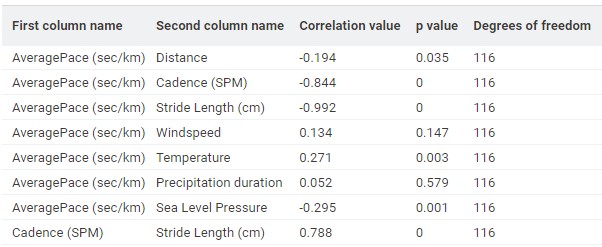
It’s interesting to see that only precipitation duration and windspeed show no significant correlation with my average pace. All other variables, such as temperature, sea level pressure, stride length, and cadence, appear to have a statistically significant relationship (p value < 0.05).
However, correlation alone doesn’t tell the full story. A correlation measures how two variables move together, but it doesn’t account for how the other variables might also affect the relationship. For example, both Stride Length and Cadence are strongly correlated with pace, but they’re also correlated (0.788) with each other.
That’s where linear regression comes in. Regression makes it possible to see the unique contribution of each variable while controlling for all the others. It helps distinguish variables that merely move together from those that truly explain differences in pace.
So while correlations give a quick sense of what’s connected, regression reveals what really matters once everything is considered together. Let’s see what happens when we bring all these variables into a single linear regression model. A linear regression, a classic yet powerful technique that tests whether changes in the dependent variable (pace per km) are linearly related to one or more independent variables.
Regression Setup
In KNIME, I used the Linear Regression Learner node. The configuration was straightforward:
- Target: Average pace (sec/km)
- Input variables: all the factors listed above
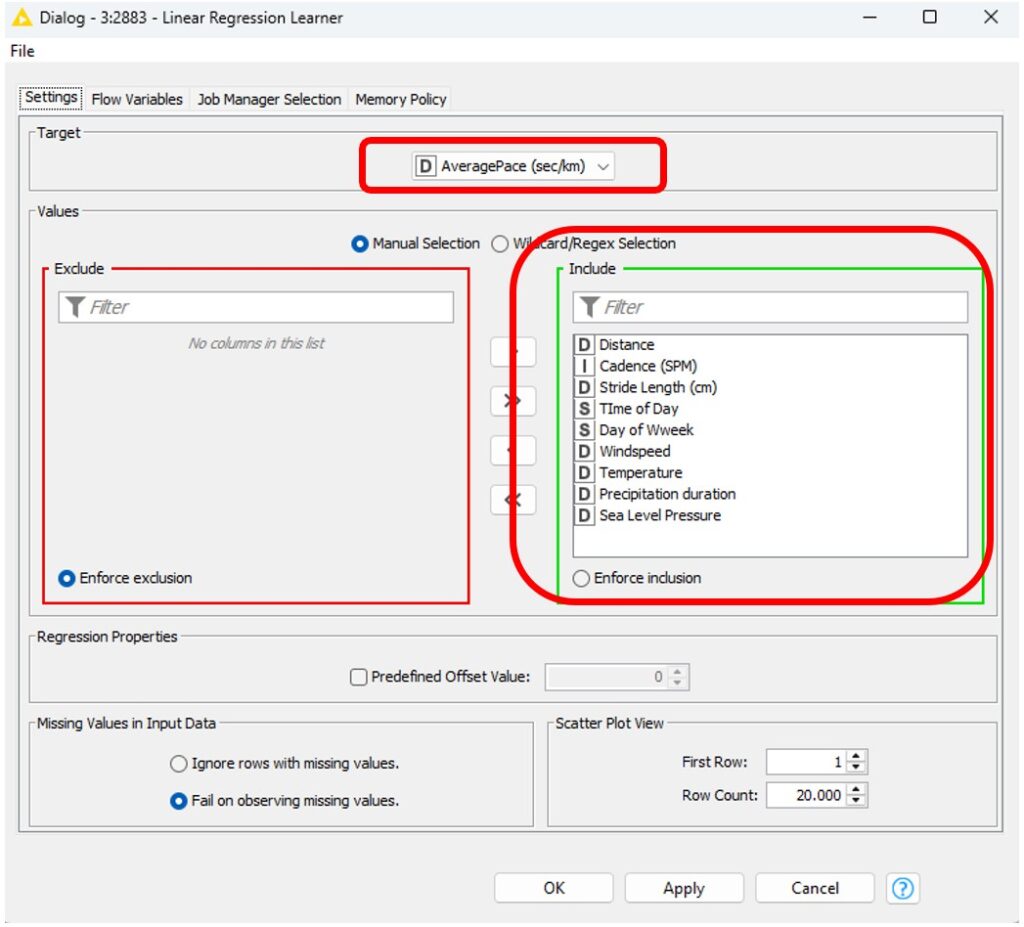
I ran the regression twice: first with the original (unstandardized) input variables, and second with z-score standardized variables (mean = 0, standard deviation = 1). Why I ran the regression twice, what makes the difference?
- Unstandardized coefficients show how much your pace changes when a variable increases by one unit (holding others constant).
- Standardized coefficients let you compare which variables have the strongest relative impact, regardless of scale or units. Larger absolute values = stronger influence.
Understanding the Regression output
In the regression output, several columns provide useful insights:
- Coeff.: The estimated effect of each variable on your pace.
- Coeff. (Standardized): The effect after normalizing all inputs to z-scores (for comparison).
- Std. Err.: How precise the estimate is (smaller is better).
- t-value: How strong the relationship is relative to noise.
- P>|t| : The probability that the observed effect is due to chance (values below 0.05 are statistically significant).
- R² / Adjusted R²: How well the model explains your pace variation (values near 1 mean an excellent fit).
The Results
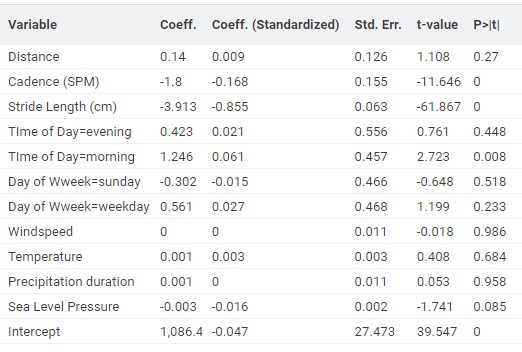
It is all about stride length and cadence
Once the regression model was fitted, the numbers told a clear story. Two variables dominate: stride length and cadence.
- Stride length (standardized coefficient = −0.855) was by far the strongest predictor. Longer strides are closely tied to faster kilometers. Increasing my average stride by just 1 cm translates into about 3.9 seconds faster per kilometer.
- Cadence (SPM) (standardized coefficient = −0,168) also has a significant impact. More steps per minute generally mean smoother, more efficient motion and better pace.
Together, these two variables explain almost all variation in my running pace, as confirmed by the R² of 0.9946, an exceptionally high model fit.
Morning runs are a bit slower
Interestingly, “Time of Day = morning” also showed a small but statistically significant effect (p = 0.008). The positive coefficient (+1.25) means I tend to run slightly slower in the morning. Maybe my body just needs a little more time to wake up before hitting its stride.
Weather and distance don’t seem to matter
I expected wind, temperature, or rain to affect my pace, but the data said otherwise. None of the weather variables turned out to be statistically significant. Once stride length and cadence are accounted for, weather conditions hardly move the needle. Even distance didn’t show a meaningful effect when the other factors were included.
Takeaway
Although the correlation analysis showed that several factors like temperature, air pressure, and distance seemed related to my pace, the regression analysis told a much clearer story. Once all variables were considered together, only stride length and cadence (SPM) truly stood out as significant predictors.
In other words: how I move matters far more than where or when I run.
Focusing on running efficiency, taking slightly longer strides and maintaining a steady cadence, is likely to yield far bigger performance gains than trying to outsmart the wind or wait for the perfect weather.
What drives your pace?
These results reflect my running data, your story might look completely different. Stride length and steps per minute clearly make the biggest difference for me, but their effects can vary depending on your body type, fitness level, and running style.
If you’re curious about what shapes your performance, try it yourself. Export the data from your sport watch, combine it with some weather data or any other relevant data-source and use my KNIME workflow as an example to build a simple regression.
You might be surprised by what really influences your pace, and what doesn’t. Start exploring, listen to your data, and maybe even to your body, because the insights you find might just change the way you run.