Love, Fear and Everything in Between – How LLMs and KNIME make sense of song lyrics
Since the 1960s, the world has changed dramatically. From the idealistic protest movements of the ’60s and ’70s, through the individualism and consumerism of the ’80s and ’90s, to the digital revolution, globalization, and increasing focus on mental health and identity in the 21st century. Each decade carries its own mood, values, and societal themes. But to what extent does the popularity of pop songs reflect these broader trends?
In this article, I dive into the lyrics of popular songs from the 1960s to today, searching for shifts in sentiment and subject matter. My solution is implemented using KNIME Analytics Platform, the open-source and free software for data analytics, and its AI extension that makes leveraging LLMs very easy.
The Top2000
Since 1999, Dutch radio station NPO Radio 2 has broadcast the Top2000 every year between Christmas and New Year’s Eve. The Top2000 is a chart, listing the 2000 “greatest pop songs of all time.” The list is compiled based on public votes.
If you’d like to read about data operations for string matching using Top2000 music data, check also my previous article “Matching ‘Non-Matching’ Strings”.
I wondered: Do the themes and sentiments of these songs change over time? Can we observe trends in the lyrics as the years go by?
The lyrics were selected from a database of 4,853 songs that appeared at least once in the Top2000 between 1999 and 2024. I managed to retrieve lyrics for 2,582 of those songs, representing about 50% of the dataset. The proportion of songs with available lyrics is relatively evenly spread across both the decades and Top2000 years.
Is this sample representative of all pop songs? That’s hard to say, just as it’s unclear how representative Top2000 voters are of the general population. Keep that in mind while interpreting the findings presented in this article.
Using KNIME and its AI Capabilities
As in many of my analyses, I used KNIME Analytics Platform. Since version 5.2, KNIME has been enriched with a KNIME AI Extension, offering capabilities for connecting to proprietary and open-source Large Language Models (LLMs), Embedding models, as well as creating and managing Vector Stores — just to mention a few.
A key advantage of the KNIME AI extension is its seamless integration with local LLMs. LLMs can be run locally, directly on your own PC or laptop, with no cost and while keeping your data safely on-prem.
For this analysis, I used Meta’s Llama 3: Instruct sourced from Ollama, a model fine-tuned to perform well on user-defined instructions and tasks. Using this local LLM in KNIME is surprisingly easy and allows us to build a powerful, fully local analysis environment — perfect for experimentation, learning, and gaining insights from large amounts of text data.
Read more about installing and leveraging a local LLM sourced from Ollama in KNIME in “How to leverage open source LLMs locally via Ollama”.
Building the KNIME Workflow
To prepare my data for analysis, I built a workflow in KNIME (see my workflow on the KNIME Hub) consisting of three main parts:
- Authentication and connection to the LLM
- Processing of input and output of the LLM
- Configuration of the LLM Prompter, the heart of the process
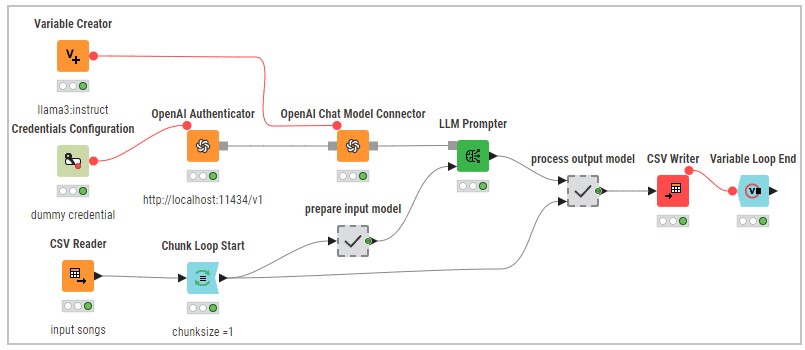
Authentication is done via the OpenAI Authenticator node. No valid credentials are needed; you can enter anything. What’s crucial is the correct base URL, pointing to your locally running LLM (http://localhost:11434/v1).
Another important setting is the “Maximum response length (tokens)” in the OpenAI Chat Model Connector, this must be big enough to fit the expected response, but not excessively large.
I set the temperature to 0.2, a low value that generally leads to more probable answers. However, variations may still occur. For example, while I expected the model to return a one-word sentiment, in 0.23% of the cases it used multiple words, and in 13.2% it capitalized the first letter against the prompt instructions.
This highlights that LLMs are non-deterministic systems and their output can vary subtly even under fixed prompts.
Engineering the Prompt
The prompt determines the model’s behavior and output, getting it right is a matter of trial and error. Run a few tests and ask yourself: Is this the kind of output I want to work with?
Here’s the final prompt I used to analyze each song:
Read the following song lyrics and determine the main theme. Choose the most fitting category from the list below. Then, explain your choice in one or two sentences.
And finally determine the sentiment of the song (positive or negative or neutral)Categories (choose one):
— Love & Relationships
— Identity & Self-Expression
— Society & Culture
— Escapism & Celebration
— Mental & Emotional StatesRespond only in valid JSON format, using the following structure:
{
“category”: “…”,
“explanation”: “…”,
“sentiment”: “…”
}
Categorizing Lyrics
The five categories weren’t randomly chosen, they were developed during a conversation with ChatGPT, where we explored how to summarize pop lyrics using universal and timeless themes.
Here are the five categories:
- Love & Relationships
Everything to do with love, from falling in love to heartbreak, from longing to breakup.
Examples: romantic love, heartbreak, unrequited love, making up/breaking up. - Identity & Self-Expression
Songs about who you are, daring to be yourself, personal growth, or struggles with identity.
Examples: self-empowerment, insecurity, authenticity, personal growth. - Society & Culture
A broader lens, protest songs, social commentary, political statements, or reflections on the world.
Examples: inequality, war, climate change, generational divides. - Escapism & Celebration
Songs about having fun, escaping reality, partying, traveling, or dreaming.
Examples: partying, summer vibes, travel, daydreaming. - Mental & Emotional States
Lyrics that explore internal experiences: emotions like fear, loneliness, hope, or depression.
Examples: anxiety, confidence, grief, joy, vulnerability.
Input and Output
Processing the so many lyrics on my laptop wasn’t that fast. So I submitted the songs one by one to the LLM Prompter using the Chunk Loop nodes, and saved them with the CSV Writer. In case my computer crashed (and yes, it did happen), I still had that part of my output that had already been processed by the LLM Prompter.
The input consisted of a record with the artist name, song title, and the lyric.
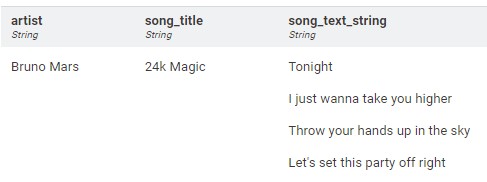
The output from the LLM Prompter was returned in JSON format, making it easy to parse and process using, for example, the JSON Path node. Wherever possible (i.e., whenever the model allows for it), it’s advisable to return model responses in JSON format, for it is much easier and faster to parse them.

Results
After building, configuring, and testing the workflow, I successfully collected both the category (with explanation) and sentiment for all 2,582 songs. This forms the basis of my analysis. I then examined how these two variables, category and sentiment, were distributed across the Top2000 from 1999 to 2024, revealing how both metrics have evolved over the past 25 years.
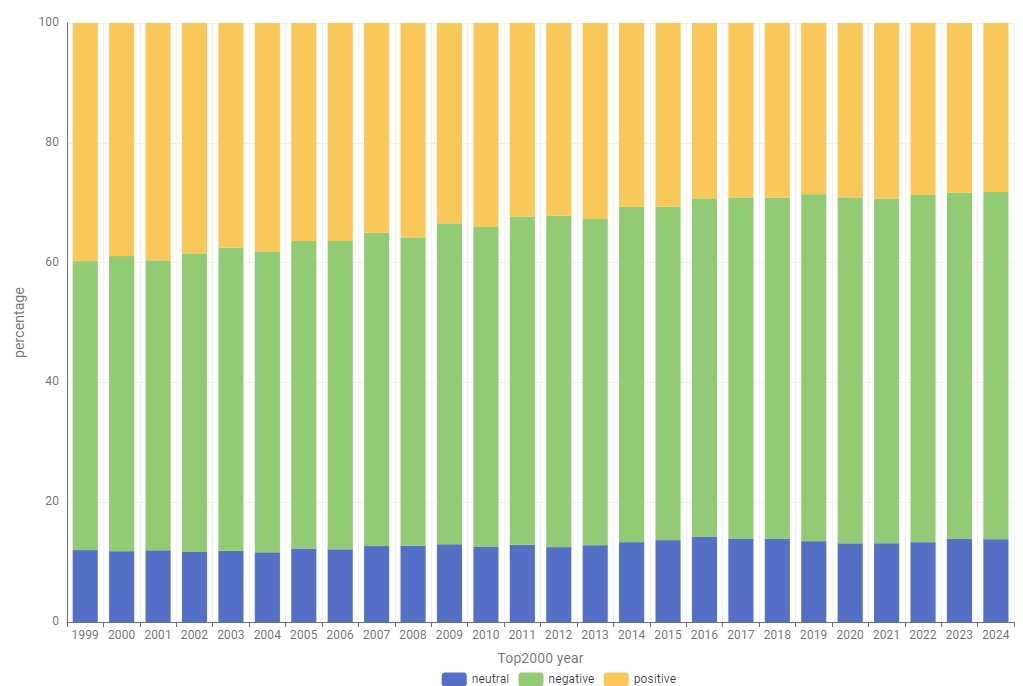
The Share of Negative Sentiment Is Growing
While the overall sentiment hasn’t shifted dramatically, there’s a clear upward trend in negative sentiment. In 1999, 48% of songs were labeled negative and 40% positive. By 2024, 58% had a negative sentiment, while the positive sentiment dropped to 28%.
“Love & Relationships” Is No Longer Dominant
Roughly 60% of all songs fall into either “Love & Relationships” or “Mental & Emotional States”. But the share of songs focusing on love and relationships has dropped from 47% in 1999 to 30% in 2024.
Meanwhile, the “Mental & Emotional States” category has grown from 16% in 1999 to 29% in 2024. Songs in “Identity & Self-Expression” have also become more prominent, increasing from 17% to 24%.
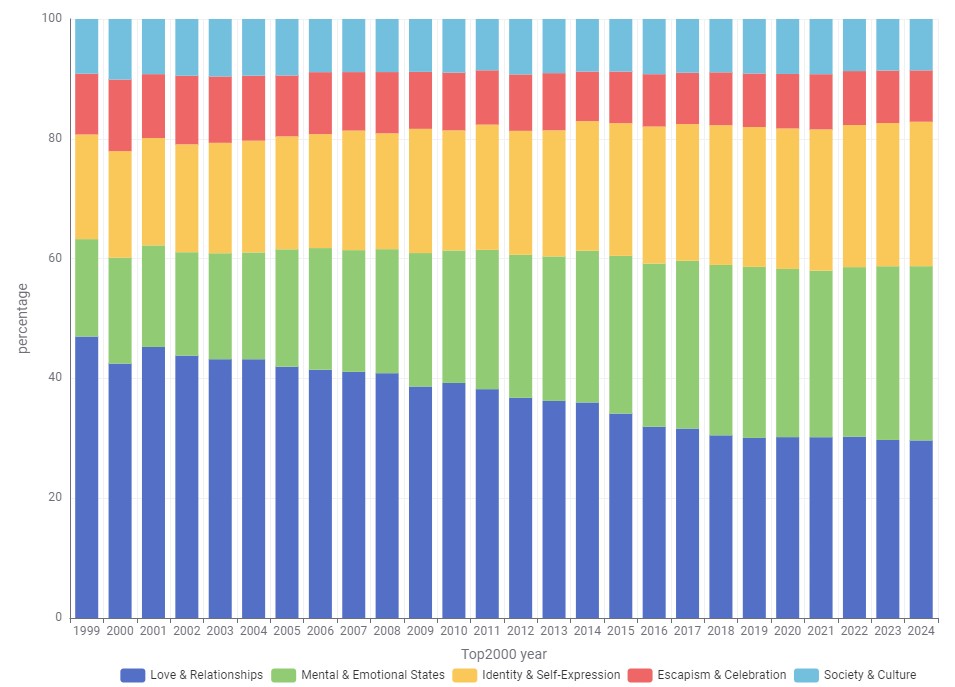
These shifts may reflect broader societal developments where the individual increasingly takes center stage.
The categories “Escapism & Celebration” and “Society & Culture” remain fairly stable over time, each holding a consistent 10% share.
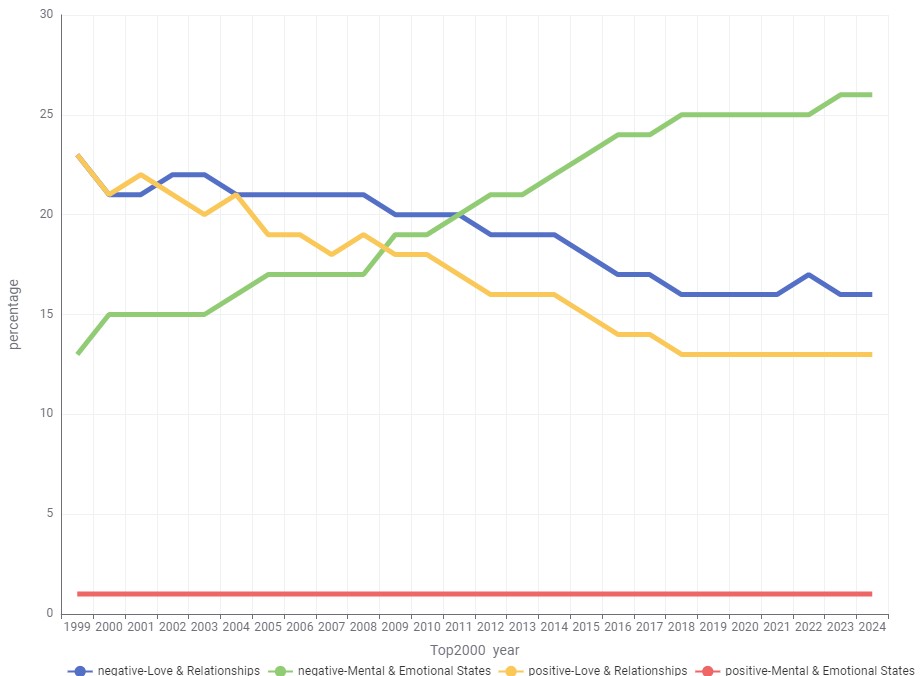
Zooming in: Mental States and Negativity
When we zoom in on the two dominant categories, “Love & Relationships” and “Mental & Emotional States”, and combine them with sentiment, one trend stands out: The share of songs in the “Mental & Emotional States” category with a negative sentiment has doubled from 13% in 1999 to 26% in 2024. This segment now represents a substantial portion of the Top2000.
Conclusion
This analysis shows how KNIME, in combination with locally hosted Large Language Models from Ollama, can be used to classify unstructured text and turn complex song lyrics into structured insights. By engineering a prompt into a reproducible workflow, it’s possible to uncover lyrical trends that reflect broader societal shifts. Most importantly, it highlights how accessible tools like KNIME and local LLMs now enable large-scale text analysis without requiring deep coding skills or cloud infrastructure, making advanced AI techniques available to a much wider audience.